
简介
模型会预测下一个token。在生成token时,模型通常会将decorder 输出的每个token的概率归一化,如果只选择概率最高的token,生成的响应会比较保守和重复。因此chatgpt通常使用temperature 来表示引入一定程度的随机性,以使生成的响应更加丰富多样。较大的temperature 会有更多机会选择非最高概率token,也可能导致生成的响应过于随机和不合理。
HuggingFace
Hugging Face 自然语言处理(NLP)的开源平台和社区,主要提供了以下几个产品和服务:
- Hub:这是一个机器学习的中心,让你可以创建、发现和协作ML项目。可以从排行榜开始,了解社区中表现较好的模型。如果你没有 GPU,你必须使用小的模型。转到文件目录并查看 .bin 文件的大小。有的项目在型号卡中也会提到所需的最低规格。PS:就像github 包含代码文件一样,这里包含代码的模型文件,git clone 时要安装Git LFS(Git Large File Storage)
- Transformers:这是一个自然语言处理的库,支持多种编程语言(如Python、JavaScript、Swift等)和框架(如PyTorch、TensorFlow等),并提供了简单易用的API,让你可以快速地加载、训练和部署模型。帮我们跟踪流行的新模型,并且提供统一的代码风格来使用BERT、XLNet和GPT等等各种不同的模型。只有configuration,models和tokenizer三个主要类,基于上面的三个类,提供更上层的pipeline和Trainer/TFTrainer,从而用更少的代码实现模型的预测和微调。
- pipeline 在底层是由 AutoModel 和 AutoTokenizer 类来实现的。AutoClass(即像 AutoModel 和 AutoTokenizer 这样的通用类)是加载模型的快捷方式,它可以从其名称或路径中自动检索预训练模型。
- ```python from transformers import MODEL_NAME # 导入模型 model = MODEL_NAME.from_pretrained(‘MODEL_NAME’) # 实例化模型,其中 MODEL_NAME 是模型的名称或路径。 inputs = xx # 准备输入数据,转换为模型支持的格式。(如 tokenizer 后的文本、图像等) outputs = model(inputs) # 调用模型并获得输出
model.save_pretrained(‘PATH’) # 将模型保存到指定路径 ```
- 在Linux下,模型默认会缓存到
~/.cache/huggingface/transformers/。所有的模型都可以通过统一的from_pretrained()函数来实现加载,transformers会处理下载、缓存和其它所有加载模型相关的细节。而所有这些模型都统一在Hugging Face Models管理。 - 最初我认为您需要为每个模型系列使用特定的Transformers和Tokenizer(例如,如果您使用T5模型系列,则对应T5Tokenizer和 T5ForConditionalGeneration),对于所有预训练模型,您可以声明一个简单的语句:
from transformers import AutoTokenizer, AutoModelForCausalLM tokenizer = AutoTokenizer.from_pretrained("databricks/dolly-v2-3b") model = AutoModelForCausalLM.from_pretrained("databricks/dolly-v2-3b")
- Inference API:这是一个服务,让你可以直接从Hugging Face的基础设施上运行大规模的NLP模型,并在毫秒级别得到响应。
- Datasets:这是一个数据集的库,让你可以获取、加载和处理超过1400个公开可用的数据集。Datasets支持多种数据类型(如文本、图像、音频等)和格式(如JSON、CSV等),并提供了高效且统一的API,让你可以快速地加载、缓存和转换数据。PS: 一开始看代码的时候,总以为是pytorch dataset
下载模型文件(一般有几个G)有多种方式
- 到huggingface 官网手动通过文件链接下载
- 可以使用
export HF_ENDPOINT=https://hf-mirror.com国内加速一下
- 可以使用
- Git LFS 下载。
git clone https://huggingface.co/THUDM/chatglm-6bPS:注意不是github 地址 - Hugging Face Hub 下载。
from huggingface_hub import snapshot_download snapshot_download(repo_id="bert-base-chinese") huggingface-cli download --resume-download --cache-dir ./cache/ --local-dir ./starcoder bigcode/starcoder- 使用transformers 库,但这种方式速度慢,且经常中断。
from transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True,mirror="tuna") model = AutoModel.from_pretrained("THUDM/chatglm2-6b",trust_remote_code=True, mirror="tuna")下载后文件会出现在
~/.cache目录下~/.cache /torch/sentence_transformers /moka-ai_m3e-base /config.json /pytorch_model.bin /huggingface/hub /models--THUDM--chatglm2-6b /blobs /snapshots /b1502f4f75c71499a3d566b14463edd62620ce9f # 某个版本的文件内容 /config.json /pytorch_model.xx.bin
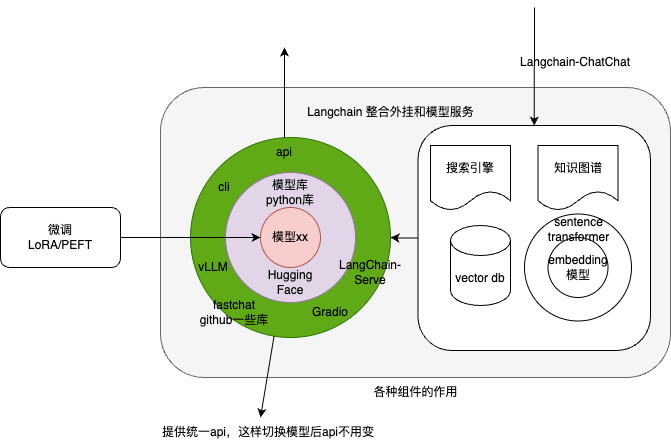
LangChain使用 HuggingFace 模型
如果只是调用模型服务,那直接使用HuggingFace库即可,但若是想和LangChain结合,还是要适配成LangChain.LLM 才能与LangChain 其它模块协同,HuggingFace 提供了LangChain.LLM 的实现。
- 使用在线模型
import os from langchain import PromptTemplate, HuggingFaceHub, LLMChain os.environ['HUGGINGFACEHUB_API_TOKEN'] = 'xx' template = """Question: {question} Answer: Let's think step by step.""" prompt = PromptTemplate(template=template, input_variables=["question"]) llm = HuggingFaceHub(repo_id="google/flan-t5-xl", model_kwargs={"temperature":0, "max_length":64}) llm_chain = LLMChain(prompt=prompt, llm=llm) question = "What NFL team won the Super Bowl in the year Justin Beiber was born?" print(llm_chain.run(question)) - 将 Hugging Face 模型直接拉到本地使用(有些模型无法在 Hugging Face 运行)
from langchain import PromptTemplate, LLMChain from langchain.llms import HuggingFacePipeline from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, AutoModelForSeq2SeqLM model_id = 'google/flan-t5-large' tokenizer = AutoTokenizer.from_pretrained(model_id) model = AutoModelForSeq2SeqLM.from_pretrained(model_id) pipe = pipeline("text2text-generation",model=model,tokenizer=tokenizer, max_length=100) local_llm = HuggingFacePipeline(pipeline=pipe) print(local_llm('What is the capital of France? ')) template = """Question: {question} Answer: Let's think step by step.""" prompt = PromptTemplate(template=template, input_variables=["question"]) llm_chain = LLMChain(prompt=prompt, llm=local_llm) question = "What is the capital of England?" print(llm_chain.run(question))
LangChain
LangChain is a framework for developing applications powered by language models. We believe that the most powerful and differentiated applications will not only call out to a language model, but will also be:
- Data-aware: connect a language model to other sources of data
- Agentic: allow a language model to interact with its environment
如果是一个简单的应用,比如写诗机器人,或者有 token 数量限制的总结器,开发者完全可以只依赖 Prompt。当一个应用稍微复杂点,单纯依赖 Prompting 已经不够了,这时候需要将 LLM 与其他信息源或者 LLM 给连接起来(PS:重点不是模型服务本身),比如调用搜索 API 或者是外部的数据库等。LangChain 的主要价值在于:
- 组件:用于处理语言模型的抽象,以及每个抽象的一系列实现。无论您是否使用 LangChain 框架的其他部分,组件都是模块化且易于使用的。PS: 既可以单独用,也可以组合用。
- 现成的链式组装:用于完成特定高级任务的结构化组件组装。一些例子包括:
- 将 LLM 与提示模板结合。
- 通过将第一个 LLM 的输出作为第二个 LLM 的输入,按顺序组合多个 LLM。
- 将 LLM 与外部数据结合,例如用于问答系统。
- 将 LLM 与长期记忆结合,例如用于聊天历史记录。
基础功能
- Model,主要涵盖大语言模型(LLM),为各种不同基础模型提供统一接口,然后我们可以自由的切换不同的模型。相关代码较少,大部分主要是调用外部资源,如 OPENAI 或者 Huggingface 等模型/API。
- 普通LLM:接收文本字符串作为输入,并返回文本字符串作为输出
- 聊天模型:将聊天消息列表作为输入,并返回一个聊天消息。支持流模式(就是一个字一个字的返回,类似打字效果)。
- Prompt,支持各种自定义模板
- 拥有大量的文档加载器,从指定源进行加载数据的,比如 Email、Markdown、PDF、Youtube …当使用loader加载器读取到数据源后,数据源需要转换成 Document 对象后,后续才能进行使用。
- 对索引的支持。对用户私域文本、图片、PDF等各类文档进行存储和检索。为了索引,便不得不牵涉以下这些能力
- 在LangChain中,所有的数据源都可以认为是Document,任何的数据库、网络、内存等等都可以看成是一个Docstore。
- 文档分割器/Text Splitters,为什么需要分割文本?因为我们每次不管是做把文本当作 prompt 发给 openai api ,还是还是使用 openai api embedding 功能都是有字符限制的。比如我们将一份300页的 pdf 发给 openai api,让它进行总结,它肯定会报超过最大 Token 错。所以这里就需要使用文本分割器去分割我们 loader 进来的 Document。
- 向量化,数据相关性搜索其实是向量运算。以,不管我们是使用 openai api embedding 功能还是直接通过向量数据库直接查询,都需要将我们的加载进来的数据 Document 进行向量化,才能进行向量运算搜索。
- 对接向量存储与搜索,向量化存储接口VectorStore, 比如 Chroma、Pinecone、Qdrand
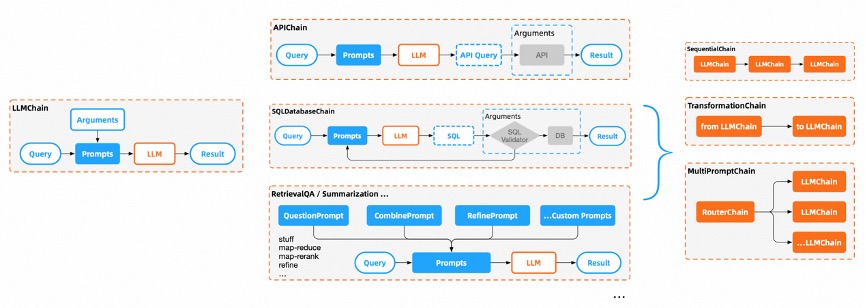
- Chains,相当于 pipeline,包括一系列对各种组件的调用,每一个从Prompt到Answer的过程,都被标准化为不同类型的LLMChain。Chain可以相互嵌套并串行执行,通过这一层,让LLM的能力链接到各行各业。 内嵌了memory、cache、callback等组件。
- LLMChain
- 各种工具Chain
- LangChainHub
如果说Prompts和Answer是水和土壤,有了CoT的理论指导加上Chains的架构就好像开渠造河,将原本由AI随意发散而不可控的推理过程固化到了Chain和Chain的连接上,让一切都回归到我们认知中流程应有的样子。
Model,主要涵盖大语言模型(LLM)
from langchain.llms import OpenAI
#Here we are using text-ada-001 but you can change it
llm = OpenAI(model_name="text-ada-001", n=2, best_of=2)
#Ask anything
llm("Tell me a joke")
# 输出
'\n\nWhy did the chicken cross the road?\n\nTo get to the other side.'
Prompt,我们可以提供提示模板作为输入。模板指的是我们希望获得答案的具体格式或蓝图。使用提示词模板的意义在于,很多提示词都会很长,里面会有很多细节,但只有一部分内容是动态的,所以应该尽可能利用模板来复用提示词,模板中可以用 {} 来引用变量。LangChain 提供了预先设计好的提示模板,可以用于生成不同类型任务的提示。然而,在某些情况下,预设的模板可能无法满足你的需求。在这种情况下,我们可以使用自定义的提示模板。PS:上层用户只需要输入关键词即可。
from langchain import PromptTemplate
# This template will act as a blue print for prompt
template = """
I want you to act as a naming consultant for new companies.
What is a good name for a company that makes {product}?
"""
prompt = PromptTemplate(input_variables=["product"], template=template,)
prompt.format(product="colorful socks")
# -> I want you to act as a naming consultant for new companies.
# -> What is a good name for a company that makes colorful socks?
| Completions接口 | Chat 接口 | |
|---|---|---|
| 模型 | OpenAI | ChatOpenAI |
| llm.predict(xx) | chat.predict_messages([SystemMessage(context=xx),HumanMessage(content=xx),AIMessage(content=xx)]) | |
| PromptTemplate | prompt = PromptTemplate.from_template(xx) text = prompt.format(xx) |
chat_prompt = ChatPromptTemplate.from_template([SystemMessagePromptTemplate.from_template(xx),HumanMessagePromptTemplate.from_template(xx)]) messages = chat_prompt.format_messages(xx) |
LLMChain ,通过链式调用的方式,把一个需要询问 AI 多轮才能解决的问题封装起来,在这个链式序列中,每个链式都有一个输入和一个输出,一个步骤的输出作为下一个步骤的输入。把一个通过自然语言多轮调用才能解决的问题,变成了一个函数调用。所有 Chain 对象共享的call和 run 方法外
chain = LLMChain(llm = llm, prompt = prompt)
chain("what is rice?")
想要通过大语言模型,完成一个复杂的任务,往往需要我们多次向 AI 提问,并且前面提问的答案,可能是后面问题输入的一部分。LangChain 通过将多个 LLMChain 组合成一个 SequantialChain 并顺序执行,大大简化了这类任务的开发工作。Langchain 的链式调用并不局限于使用大语言模型的接口。
- LLMMathChain 能够通过 Python 解释器变成一个计算器,让 AI 能够准确地进行数学运算。
- 通过 RequestsChain,我们可以直接调用外部 API,然后再让 AI 从返回的结果里提取我们关心的内容。
- TransformChain 能够让我们根据自己的要求对数据进行处理和转化,我们可以把 AI 返回的自然语言的结果进一步转换成结构化的数据,方便其他程序去处理。
- VectorDBQA 能够完成和 llama-index 相似的事情,只要预先做好内部数据资料的 Embedding 和索引,通过对 LLMChain 进行一次调用,我们就可以直接获取回答的结果。
- Langchain 里有 SQLDatabaseChain 可以直接让我们写需求访问数据库。 这些能力大大增强了 AI 的实用性,解决了几个之前大语言模型处理得不好的问题,包括数学计算能力、实时数据能力、和现有程序结合的能力,以及搜索属于自己的资料库的能力。你完全可以定义自己需要的 LLMChain,通过程序来完成各种任务,然后合理地组合不同类型的 LLMChain 对象,来实现连 ChatGPT 都做不到的事情。
Memory
在 LangChain 中,链式和代理默认以无状态模式运行,即它们独立处理每个传入的查询。然而,在某些应用程序(如聊天机器人)中,保留先前的交互记录对于短期和长期都非常重要。这时就需要引入 “内存” 的概念,则需要我们自行维护聊天记录,即每次把聊天记录发给 gpt。PS:一般情况下,记忆模型更多的是应用于会话/chat场景,BaseMemory下一层只有一个子类 BaseChatMemory。
- 我们可以通过 BufferWindowMemory 记住过去几轮的对话,通过 SummaryMemory 概括对话的历史并记下来。也可以将两者结合,使用 BufferSummaryMemory 来维护一个对整体对话做了小结,同时又记住最近几轮对话的“记忆”。
- 可以使用 EntityMemory,它会帮助我们记住整个对话里面的“命名实体”(Entity),保留实际在对话中我们最关心的信息。
from langchain.memory import ChatMessageHistory
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(temperature=0)
history = ChatMessageHistory() # 初始化 MessageHistory 对象
history.add_ai_message("你好!") # 给 MessageHistory 对象添加对话内容
history.add_user_message("中国的首都是哪里?")
ai_response = chat(history.messages) # 执行对话
print(ai_response)
Agent
在Chain中行动序列是硬编码的,而Agent则采用语言模型作为推理引擎来确定以什么样的顺序采取什么样的行动。
Turn your LLMs into reasoning engines. the core idea of agents is to use an LLM to choose a sequence of actions to take. in chains, a sequence of actions is hardcoded(in code). In agents a language model is used as a reasoning engine to determine which actions to take and in which order.
从“告诉计算机要做什么”的编程范式向“告诉计算机我们想要什么”的范式的转变。人类之所以在地球上显得独特,一个重要原因是我们更擅长使用工具。无论是网络上的还是现实世界里面的实体机器人,只要给大模型足够的「说明书」,大模型就可以把它纳入到解决方案工具箱,用来回答或者执行你用自然语言提出的问题 or 任务。
某些应用可能需要不仅预定的 LLM(大型语言模型)/其他工具调用顺序,还可能需要根据用户的输入确定不确定的调用顺序。这种情况下涉及到的序列包括一个 “代理(Agent)”,该代理可以访问多种工具。根据用户的输入,代理可能决定是否调用这些工具,并确定调用时的输入。如果我们真的想要做一个能跑在生产环境上的 AI 聊天机器人,我们需要的不只一个单项技能,对于有很多个不同的“单项技能”,AI 要能够自己判断什么时候该用什么样的技能(意图识别问题)。通过“先让 AI 做个选择题”的方式,Langchain 让 AI 自动为我们选择合适的 Tool 去调用。我们可以把回答不同类型问题的 LLMChain 封装成不同的 Tool,也可以直接让 Tool 去调用特定能力的LLMChain 等工具。比如
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.llms import OpenAI
from langchain.agents import AgentType
llm = OpenAI(temperature=0,max_tokens=2048) # 加载 OpenAI 模型
tools = load_tools(["serpapi"]) # 加载 serpapi 工具
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True) # 工具加载后都需要初始化,verbose 参数为 True,会打印全部的执行详情
agent.run("What's the date today? What great events have taken place today in history?") # 运行 agent
实战
- 完成一次问答
from langchain.llms import OpenAI llm = OpenAI(model_name="text-davinci-003",max_tokens=1024) llm("怎么评价人工智能") - 通过 Google 搜索并返回答案。 用agent
- 对超长文本进行总结。 我们通常的做法就是直接发给 api 让他总结。但是如果文本超过了 api 最大的 token 限制就会报错。这时,我们一般会进行对文章进行分段,比如通过 tiktoken 计算并分割,然后将各段发送给 api 进行总结,最后将各段的总结再进行一个全部的总结。
loader = UnstructuredFileLoader("/content/sample_data/data/lg_test.txt") # 导入文本 document = loader.load() # 将文本转成 Document 对象 text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500,chunk_overlap = 0) # 初始化文本分割器 split_documents = text_splitter.split_documents(document) # 切分文本 llm = OpenAI(model_name="text-davinci-003", max_tokens=1500) # 加载 llm 模型 chain = load_summarize_chain(llm, chain_type="refine", verbose=True) # 创建总结链 chain.run(split_documents[:5]) # 执行总结链,(为了快速演示,只总结前5段) - 构建本地知识库问答机器人
loader = DirectoryLoader('/content/sample_data/data/', glob='**/*.txt') # 加载文件夹中的所有txt类型的文件 documents = loader.load() # 将数据转成 document 对象,每个文件会作为一个 document text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0) # 初始化加载器 split_docs = text_splitter.split_documents(documents) # 切割加载的 document embeddings = OpenAIEmbeddings() # 初始化 openai 的 embeddings 对象 docsearch = Chroma.from_documents(split_docs, embeddings) # 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询 qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=docsearch.as_retriever(), return_source_documents=True) # 创建问答对象 result = qa({"query": "科大讯飞今年第一季度收入是多少?"}) # 进行问答 print(result)
向量数据库
当我们把通过模型或者 AI 应用处理好的数据喂给它之后(“一堆特征向量”),它会根据一些固定的套路,例如像传统数据库进行查询优化加速那样,为这些数据建立索引。避免我们进行数据查询的时候,需要笨拙的在海量数据中进行。
本地
faiss 原生使用
# 准备数据
model = SentenceTransformer('uer/sbert-base-chinese-nli')
sentences = ["住在四号普里怀特街的杜斯利先生及夫人非常骄傲地宣称自己是十分正常的人",
"杜斯利先生是一家叫作格朗宁斯的钻机工厂的老板", "哈利看着她茫然地低下头摸了摸额头上闪电形的伤疤",
"十九年来哈利的伤疤再也没有疼过"]
sentence_embeddings = model.encode(sentences)
# 建立索引
dimension = sentence_embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(sentence_embeddings)
# 检索
topK = 2
search = model.encode(["哈利波特猛然睡醒"]) # 将要搜索的内容“哈利波特猛然睡醒”编码为向量
D, I = index.search(search, topK) # D指的是“数据置信度/可信度” I 指的是我们之前数据准备时灌入的文本数据的具体行数。
print(I)
print([x for x in sentences if sentences.index(x) in I[0]])
faiss 与LangChain 集合,主要是与 LangChain 的 document和 Embeddings 结合。 faiss 本身只存储 文本向量化后的向量(index.faiss文件),但是vector db对外使用,一定是文本查文本,所以要记录 文本块与向量关系(index.pkl文件)。此外,需支持新增和删除文件(包含多个文本块),所以也要支持按文件删除 文本块对应的向量。
from langchain.document_loaders import TextLoader
# 录入documents 到faiss
loader = TextLoader("xx.txt") # 加载文件夹中的所有txt类型的文件
documents = loader.load() # 将数据转成 document 对象,每个文件会作为一个 document
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents) # 切割加载的 document
embeddings = OpenAIEmbeddings() # 初始化 openai 的 embeddings 对象
db = FAISS.from_documents(docs, embeddings) # 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 faiss 向量数据库,用于后续匹配查询
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].page_content)
简单的源码分析
# 根据文档内容构建 langchain.vectorstores.Faiss
vectorstore.base.from_documents(cls: Type[VST],documents: List[Document], embedding: Embeddings, **kwargs: Any,) -> VST:
"""Return VectorStore initialized from documents and embeddings."""
texts = [d.page_content for d in documents]
metadatas = [d.metadata for d in documents]
return cls.from_texts(texts, embedding, metadatas=metadatas, **kwargs)
# Embeds documents.
embeddings = embedding.embed_documents(texts)
cls.__from(texts,embeddings,embedding, metadatas=metadatas,ids=ids,**kwargs,)
# Initializes the FAISS database
faiss = dependable_faiss_import()
index = faiss.IndexFlatL2(len(embeddings[0]))
vector = np.array(embeddings, dtype=np.float32)
index.add(vector)
# 建立id 与text 的关联
documents = []
if ids is None:
ids = [str(uuid.uuid4()) for _ in texts]
for i, text in enumerate(texts):
metadata = metadatas[i] if metadatas else {}
documents.append(Document(page_content=text, metadata=metadata))
index_to_id = dict(enumerate(ids))
# Creates an in memory docstore
docstore = InMemoryDocstore(dict(zip(index_to_id.values(), documents)))
return cls(embedding.embed_query,index,docstore,index_to_id,normalize_L2=normalize_L2,**kwargs,)
save_local:
faiss = dependable_faiss_import()
faiss.write_index(self.index, str(path / "{index_name}.faiss".format(index_name=index_name)))
with open(path / "{index_name}.pkl".format(index_name=index_name), "wb") as f:
pickle.dump((self.docstore, self.index_to_docstore_id), f)
在线
Pinecone 是一个在线的向量数据库。所以,我可以第一步依旧是注册,然后拿到对应的 api key。
from langchain.vectorstores import Pinecone
# 从远程服务加载数据
docsearch = Pinecone.from_existing_index(index_name, embeddings)
# 录入documents 持久化数据到pinecone
# 初始化 pinecone
pinecone.init(api_key="你的api key",environment="你的Environment")
loader = DirectoryLoader('/content/sample_data/data/', glob='**/*.txt')
documents = loader.load() # 将数据转成 document 对象,每个文件会作为一个 document
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=0)
split_docs = text_splitter.split_documents(documents) # 切割加载的 document
docsearch = Pinecone.from_texts([t.page_content for t in split_docs], embeddings, index_name=index_name) # 持久化数据到pinecone
LangChain + GPTCache =兼具低成本与高性能的 LLM 未读。