强化学习细节(下):策略梯度、Actor-Critic 与训练机制
简介
一些基础概念:
- $\pi$(Policy,策略):即LLM模型
- $\theta$(Parameter,参数):即模型参数
- s(State,交互状态):即上文,初始状态即为$s_1$
- a(Action,交互行为):即输出的token,可以简单理解为每个字符。(实际上一个字不等于一个token)
- $\tau$(Trajectory,轨迹):$\tau = { s_1,a_1,r_1,s_2,a_2,r_2,…,s_T,a_T,r_T }$
Policy Gradient(策略梯度)
李宏毅老师对Policy Gradient的讲解,最原始的Policy Gradient 直接$A_t=G_t$

The Definitive Guide to Policy Gradients in Deep ReinforcementLearning:Theory, Algorithms and Implementations Policy Gradient 论文综述。
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Reward Function(奖励函数定义,即输出序列$\tau$ 能获得的奖励),用于评估某个状态/动作序列的好坏:
\[R(\tau) = \sum_{t=1}^{T} r_t\]因为actor输出有一定的随机性,即对与同一个$s_t$,actor不一定每次都输出$a_t$,自然each $\tau$ has a probability to be sampled(PS:采样出来的数据分布不一定是真实的数据分布). 这个probability用$p_\theta(\tau)$ 或 $p(\tau \mid \theta)$ 表示,连带$R(\tau)$也是随机的(所以不能单纯用标量,要计算期望),所以模型参数 $\theta$ 下的Expected Reward(期望奖励)表示为sum over all possible trajectory:
\[\overline{R}_\theta = \sum_{\tau} R(\tau) p_\theta(\tau)\]综上,我们希望调整模型参数 $ \theta $ 使这个期望奖励越大越好,因此可得Policy Gradient公式如下,期望做gradient ascent最大化期望奖励:
\[\nabla \overline{R}_\theta = \sum_{\tau} R(\tau) \nabla p_\theta(\tau)\]其中 $R(\tau)$ 来自environment 反馈(it can even be a black box),跟$\theta $没关系,所以做gradient的时候只对$p_\theta(\tau)$ 做gradient即可。
我们分别来看 $R(\tau)$ 和 $p_\theta(\tau)$ 可以被约等为什么样子。
从轨迹奖励到action得失
\[\nabla \overline{R}_\theta = \sum_{\tau} R(\tau) \nabla p_\theta(\tau) = \sum_{\tau} R(\tau) p_\theta(\tau) \frac {\nabla p_\theta(\tau)}{p_\theta(\tau)} = \sum_{\tau} R(\tau) p_\theta(\tau) \nabla \log p_\theta(\tau) \quad \text{\# Note: } \nabla f(x) = f(x) \nabla \log f(x)\]
直接对$p_\theta(\tau)$ 求导无法计算,$R(\tau) p_\theta(\tau)$是期望形式,可以通过采样足够多的轨迹来估计。
\[\sum_{\tau} R(\tau) p_\theta(\tau) \nabla \log p_\theta(\tau) \approx \frac{1}{N} \sum_{n=1}^{N} R(\tau^n) \nabla \log p_\theta(\tau^n) \quad \text{\# 实际上就是N个sample轨迹近似期望}\]接下来的问题是如何计算 $\nabla \log p_\theta(\tau^n)$, 其中,模型参数$\theta$ 下生成序列$\tau$ 的概率如下:
\[p(\tau \mid \theta) = p_\theta(\tau) = p(s_1) p_\theta(a_1|s_1) p(s_2|s_1, a_1) \ldots = p(s_1) \prod_{t=1}^{T} p_\theta(a_t|s_t) p(s_{t+1}|s_t, a_t)\]轨迹概率可以分解为动作条件概率的连乘,对数概率可以拆成每一步的 log 概率之和。

忽略掉跟 $\theta$ 无关的项( 环境无法作用gradient 所以可以移除)

| $\nabla p_\theta(\tau)$ 转换为 $\nabla p_\theta(a_t^n | s_t^n)$ 之后可以通过实际采样到的 (s, a) 对来计算。 |
其中(用到了对数求导),分母$p_\theta(a_t \mid s_t)$ 体现了重要性比重:小概率但被采样到的动作,对梯度更新影响会更大(因为这说明策略应该更重视它)。避免了在采样过程中采到很多奖励值很低但是出现频次高的动作,造成模型对这种低奖励值高频次动作的偏好。 整体而言,相当于用$p_{\theta}(a_t \mid s_t)$做了某种归一化。

直观理解:在某个state(上文)下执行某个action(token)使得最后整个输出$ \tau$ 的reward是正的时候,我们应该增加这个输出的几率,反之减少。each training data is weighted by $R(\tau^n). $ PS:rl就是,判断哪个输出更好,把这个输出的概率提高,花活在于提高多少。可以给action model 每个token算loss 了。进而是不是可以理解为rlhf和sft的反馈粒度都是token?
以上是REINFORCE 算法的核心更新公式,在此基础上,可以引入 baseline(不影响期望,减少方差)、优势函数(A3C, PPO 等方法),改进收敛效果。
$R(\tau)$可以被约等为什么样子
如果仔细看上述公式,首先,它并没有告诉我们轨迹中某个单独的动作到底好不好,其次会发现 $ R(\tau) $ 即reward恒为正的情况,那会导致一直在增加任何token的输出概率。我们希望调小概率时,reward应该是个负的。直观的想法,如果我见过一批reward,减去他们的均值就好了,这个方法叫REINFORCE with baseline,让reward有正有负,这对rl的训练效率至关重要。这个方法搞出来的均值baseline不一定是最好的,我们想知道的是此刻状态对应的价值,均值没有这样的物理意义,是不是可以用一个NN模型来预估出这个价值呢?这就是Actor-Critic方法。Actor就是你的动作概率模型,Critic就是用一个NN在算这个baseline,或者我们叫他value-base的model。如果不用一个model来估计状态的价值,还有什么好办法?那你就基于每一条原始样本生成一组序列,用他们的reward均值作为baseline,这种方法叫self-critic,它利用了蒙特卡洛方法代替了TD error。
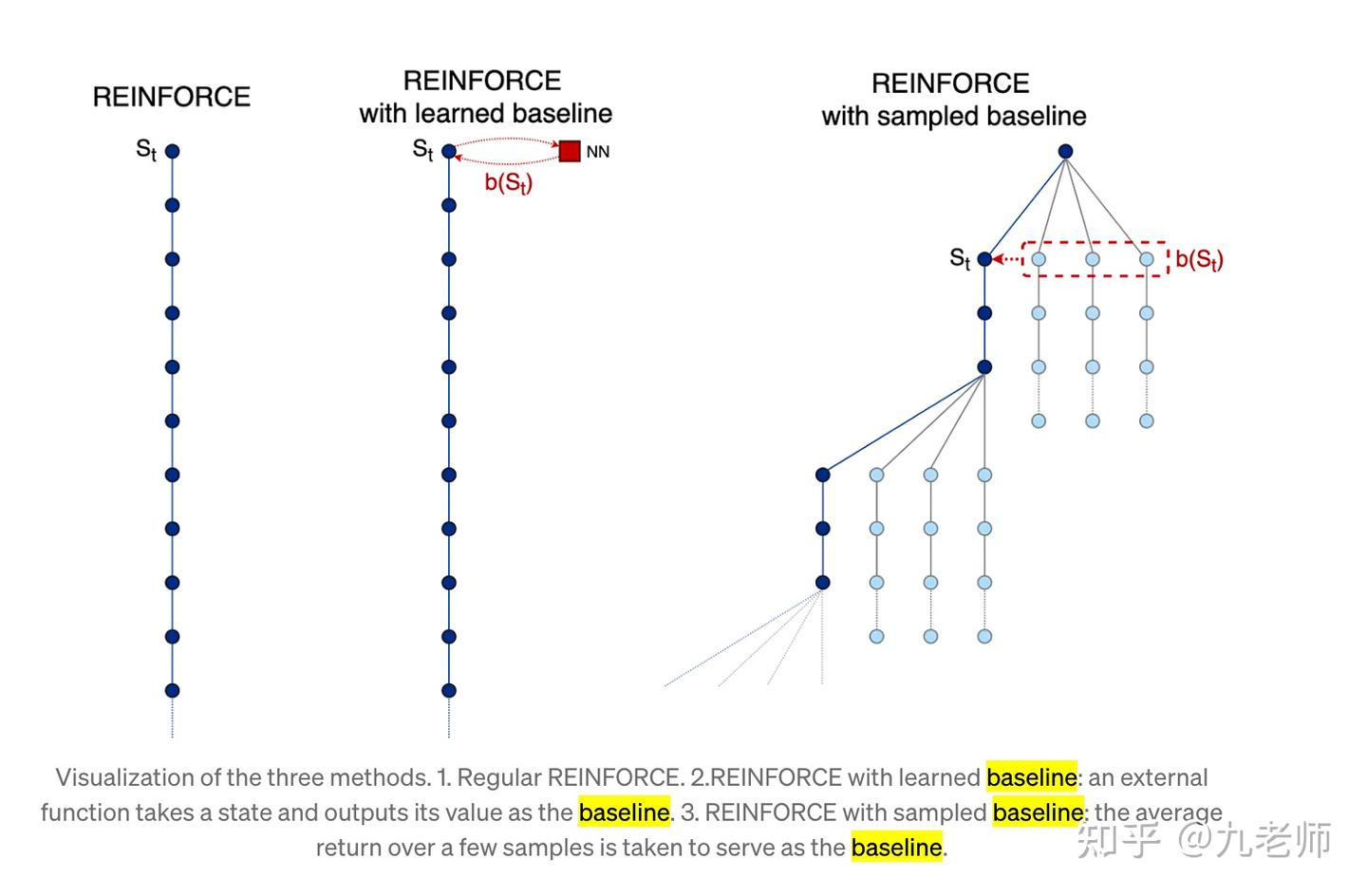
我们实际操作中是用sample的方式来训练,这就导致某些项实际上因为没被sample到(只是没被采样到,并不代表它们不好)而导致输出概率下降(实际ground truth是要提升)。所以我们希望引入一个baseline(b)让reward不是恒为正。公式变成如下:
\[\nabla \overline{R}_\theta = \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} (R(\tau^n) - b) \nabla \log p_\theta(a_t^n \mid s_t^n)\]通常我们可以将baseline设置为reward的期望值,即 $ b \approx E[R(\tau)] $。
那为什么可以“随手”减一个 baseline、结果还对?因为减 baseline 不改变梯度的期望(无偏),只改变方差——前提是 $b$ 不依赖于当前要评估的那个 action(可以依赖状态 $s$)。一行就能证:
\[E_{a \sim p_\theta}[\nabla \log p_\theta(a \mid s)\cdot b] = b\sum_a p_\theta(a \mid s)\,\nabla \log p_\theta(a \mid s) = b\sum_a \nabla p_\theta(a \mid s) = b\,\nabla \sum_a p_\theta(a \mid s) = b\,\nabla 1 = 0\]两个关键步:$p_\theta \cdot \nabla \log p_\theta = \nabla p_\theta$(对数求导反过来用),以及 $\sum_a p_\theta(a \mid s) = 1$ 求梯度后恒为 0。所以 baseline 这一项对期望梯度的贡献恒为 0,怎么减都不会把梯度“减偏”。
这条结论很重要:减 baseline 是一次“免费的方差削减”——无论 $b$ 怎么挑都不引入偏差,所以可以放心去挑一个能把方差压到最小的 $b$。后面用 NN 估的 $V(s)$(critic),或用同一道题一组样本的 reward 均值(GRPO 的组内均值)来当 baseline,都满足“不依赖被评估的那个 action”,因此都还是无偏的;区别只在方差降得多不多、以及估这个 baseline 要花多少成本。真正的偏差,是后面 critic 用 bootstrap($r + \gamma V(s’)$ 里带上自己尚不准的估计 $V$)才引入的——那一步才进入上篇「有偏与无偏」里说的 bias-variance 权衡;减 baseline 本身还停在“无偏”这一侧。这背后其实是一句更朴素的直觉——奖励的绝对水平无意义,只有相对(advantage)有意义:给所有 reward 同时加减一个常数,梯度的期望纹丝不动,就像考试只看你“比平均高几分”,整张卷子按 100 还是 1000 分制都不影响名次。
我们知道最终输出的是一个序列 $ \tau $,且在算reward时是以 $ \tau $ 的粒度计算的(episode-level reward)(PS:reward只能告诉我们哪个$ \tau $ 更好)。即使整体的reward是正的,也不意味着序列中的每一个action都是有收益的(如:说了一串废话,最后才说对结果)。因此,更合理的做法是我们需要给每一个action合适的credit(action/token-level reward)。
首先,我们会有一些假设(注意:并不一定什么情况下都适用,应根据具体情况使用不同的reward function):
-
reward应单独为每个action计算(前面的)
\[R(\tau^n) \rightarrow \sum_{t'=t}^{T_n} r_{t'}^n \quad \text{\# 计算当前action后所有reward的总和作为当前action的reward}\] -
越快完成任务应越重要,距离越远贡献越小
\[R(\tau^n) \rightarrow \sum_{t'=t}^{T_n} r_{t'}^n \rightarrow \sum_{t'=t}^{T_n} \gamma^{t'-t} r_{t'}^n \quad \text{\# } \gamma \text{为时间衰减函数}\]
实际上 $R(\tau^n) - b$ 这一项其实是在算在某个state下执行某个action比执行其他action有多好,也就是我们常说的Advantage Function,可以表示为 $A^\theta(s_t, a_t)$ ,因此综上公式可以写作:
\(\nabla \overline{R}_\theta \approx \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} A^\theta(s_t, a_t) \nabla \log p_\theta(a_t^n \mid s_t^n)\) \(= E_{(s_t, a_t) \sim \pi_\theta} [A^\theta(s_t, a_t) \nabla \log p_\theta(a_t^n \mid s_t^n)]\)
前文提到 each training data is weighted by $R(\tau^n)$,从上述公式我们看到each action is weighted by $A^\theta(s_t, a_t)$. 此时所有$a_t$的一样$A_t$,都是$R(\tau^n) - b$。
在 LLM RL 中,奖励通常是一个 scalar reward( sequence-level ),然而,由于序列级似然的数值范围极大,且由此带来的梯度估计具有极高的方差,Sequence-level Objective 很难优化。LLM RL 算法通常采用 Token-level Objective。$\mathcal{J}^{\text{token}}(\theta) \approx \mathcal{J}^{\text{seq}}(\theta)$,提高 LLM RL 稳定性的方法可以理解为:如何维持这一近似的有效性。
actor-critic
PPO理论推导+代码实战 建议细读。
Actor-Critic架构为什么要有Critic呢?这就涉及强化学习的算法稳定性问题。与监督学习(SL)相比,RL实际上是很难稳定的一类训练机制。大致的原因如下:
- RL本身是处理动态系统的最优控制问题,而SL是处理一个静态优化问题。动,就比静更难处理。
- 加上RL的数据非稳态,Env-agent交互机制的数据采集量少,这使得梯度计算的方差更大,方差一大就容易偏离预期目标,算法就容易跑飞了。主流的强化学习算法是怎么解决这一问题的呢?加上Critic,使用State-value function或者Action-value function稳定策略梯度的计算过程。更高级一些的算法是采用Advantage Function,也就是加上了Baseline,增加梯度计算的稳定性。这是AC算法总是优于REINFORCE算法的原因之一。
- 如果没有Critic,PPO只能使用蒙特卡洛的完整轨迹回报(高方差)或单纯依赖即时奖励(短视),导致训练低效甚至失败。Critic的引入使得PPO能通过时序差分(TD)学习高效地估计价值,平衡偏差与方差。 PS: 配套的actor-critic 架构就得有actor model 和critic model
为何引入critic
A用 $A=G_t$, $A=G_t^{\prime}$,$A=G_t^{\prime}-b$(此处b 是一个恒定值) 这类公式直接算不太靠谱, 所以就想着用一个network 来估计baseline,即$V^\theta(s)$。它是一个Value function(也就是critic network),输入是s(注意不是(s,a)),输出是一个scalar,表示针对 actor $\theta$,the discounted cumulated reward expects to be obtained after seeing s。PS: 就好比仅看当前棋局(不是判断走下一步)就给出输赢的概率。
critic 如何用在训练actor上?将critic scalar/score作为baseline。A用 $G_t^{\prime} - V^\theta(s)$来表示。

$V^\theta(s)$ 可以认为看到s后所有动作a带来的return均值

这里有个问题,$G_t^{\prime}$ 只是s 采取动作$a_t$ 后某一个动作序列(sample)的return,可能这个sample 特别好或特别坏,所以不能充分反应$a_t$ 的好坏,因此把$G_t^{\prime}$ 换一下,用平均减平均,A用 $r_t + V^\theta(s_{t+1}) - V^\theta(s)$来表示。也就是用 advantage 的 Actor-Critic(习惯写作 A2C,Advantage Actor-Critic)。这里要避免一个常见误称:A3C 的第一个 A 是 Asynchronous,指的是多个 worker 异步并行地采样和更新,是一种工程上的并行架构——跟这里这个单步优势公式没有关系,套不套异步是另一回事。


actor 和critic都是一个network,他们输入都是一样的,都要理解s(棋谱、游戏、llm),actor 输出action,critic 输出scalar,它们network的前大半一般是一样的。
reward shaping。到目前,rl 的过程就是收集一系列<s,a,r>,对r进行整理后得到一系列<s,a,A>,之后就可以训练actor。但我们特别担心一个情况(sparse reward问题):大多数时候$r_t$都是0(人生很多时候何尝不是这样)。此时要(除了env真正的reward之外)提供一些额外的reward(如何定义reward 需要domain knowledge)。就好比孩子study原本env $r_{t+1} = -1$ 孩子不开心,你通过给他一个棒棒糖,改变了study的reward。
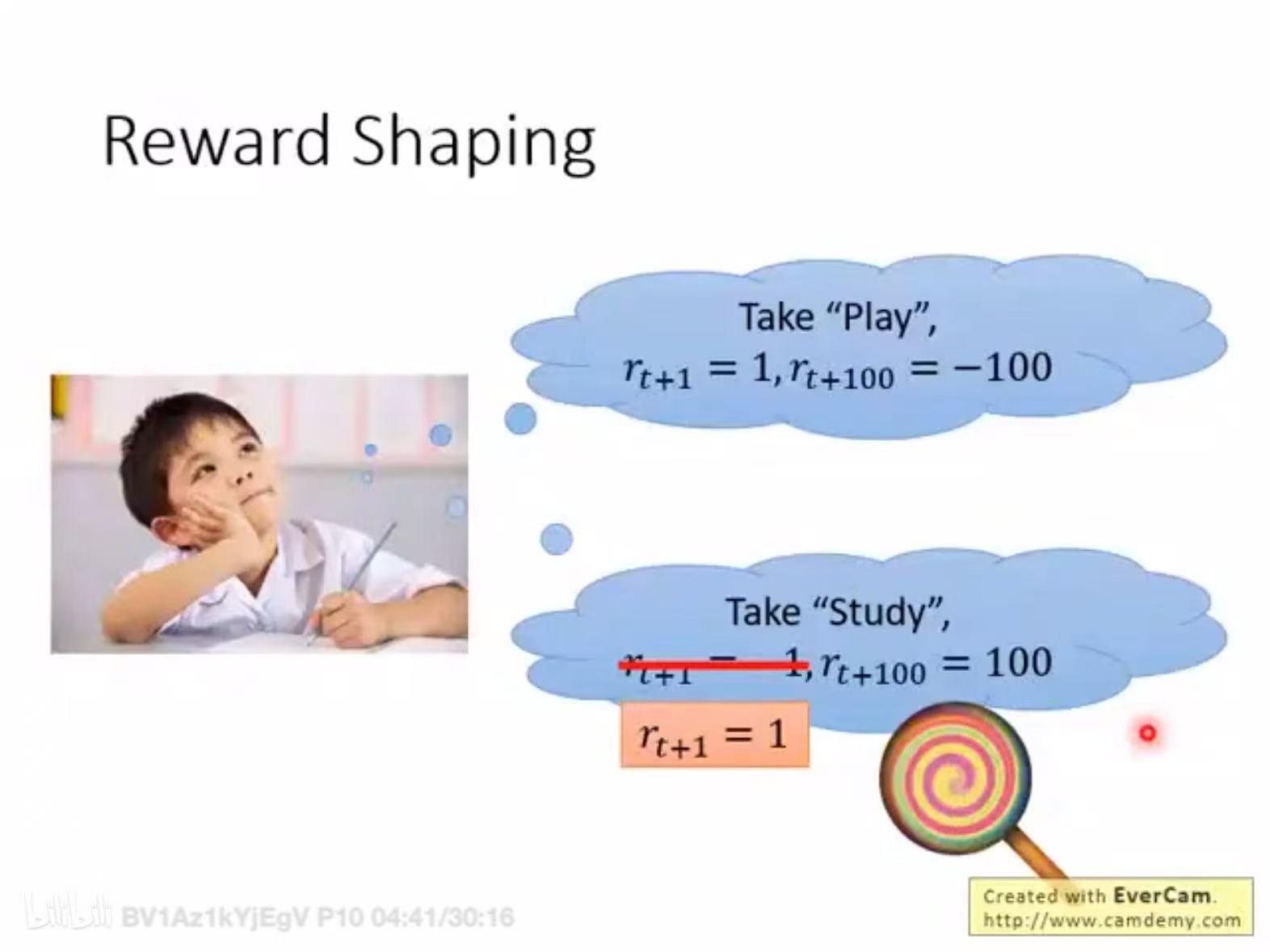
PS:此时每个$a_t$的$A_t$不同了,$A_t = R_t - V(s_t)$
把前面两种 advantage 写法连起来:它们其实是同一个东西的两端。 先把记号补全:动作价值 $Q(s,a)$ = 在状态 $s$ 选了动作 $a$ 之后的期望回报;状态价值 $V(s)$ = 在 $s$ 下不指定动作时的平均期望回报。优势函数就是两者之差:
\[A(s,a) = Q(s,a) - V(s)\]含义是“选这个动作”比“这个状态的平均水平”好多少。再由 Bellman,$Q(s,a) = E[\,r + \gamma V(s’)\,]$,代进去:
\[A(s,a) = \underbrace{r + \gamma V(s') - V(s)}_{=\ \delta_t,\ \text{即 TD error}}\]也就是说,上面那个一步形式 $r+\gamma V(s’)-V(s)$ 并不是另起炉灶,它就是单步优势,而且恰好等于 TD 误差 $\delta_t$——这是个恒等式,不是巧合(严格讲 $A=E[\delta_t]$,单次采样就用 $\delta_t$ 这一个样本去估它)。这顺带解释了一件容易绕晕的事:训练 critic 用的 $\delta_t$,和更新 actor 用的单步 advantage,为什么长得一模一样——它们本就是同一个量,只是一个拿去回归 $V$、一个拿去加权 $\nabla\log\pi$。
于是前面两种 advantage 落在同一根轴的两端:
- $A = G_t^{\prime} - V(s)$:用真实采样的整条 return $G_t^{\prime}$ → 蒙特卡洛端,无偏但高方差;
- $A = r + \gamma V(s’) - V(s) = \delta_t$:只看一步、其余全靠 $V$ 估计 → TD 端,低方差但有偏(偏就偏在 bootstrap 的那个还不准的 $V$ 上)。
这正是上篇「有偏与无偏」那条 bias-variance 轴。而下一节的 GAE,就是拿一个 $\lambda$ 在这条 MC↔TD 轴上滑动、取一个折中。
GAE
GAE是在 Actor-Critic 里,继续优化 Advantage 的估计。
TD偏差大但方差小,Monte Carlo偏差小但方差大。GAE 把多步 TD 残差按权重叠起来,在 bias / variance 之间调平衡,目的是在估计优势函数时,降低方差、同时控制偏差。PS:在只有终点奖励(如 0/1)的情况下,稳定、高效地把最终奖励“分摊”到每一个 token 的决策上。在 PPO 中,真正用来更新 policy 的不是 reward,而是 Advantage。如何估计每个action的$A_t$。
在训练开始阶段, $V_{\pi}$很有可能无法刻画真实的状态价值,我们可以选择少信任$V_{\pi}$的计算结果,将 $V_{\pi}(s_{t+1})$展开得:
\[r_t + \gamma V_{\pi}(s_{t+1}) - V_{\pi}(s_t) = -V_{\pi} + \sum_{l=0}^{\infty} \gamma^l r_{t+l}\]其中,$r_t,r_{t+1},r_{t+2},…$都是我们某次采样得到的即时奖励数据。如果$V_{\pi}$不准,那就信任实际采样结果,这样至少不会对优势函数的估计出现偏差。
\[A_t^{GAE} = \sum_{l=0}^{\infty} (\gamma\lambda)^l \delta_{t+l}\]\(\delta_{t+l} = r_t + \gamma V_{\pi}(s_{t+1}) - V_{\pi}(s_t)\) 当 $\lambda$ 接近0时,$A_t^{GAE}$ 退化成一步TD误差:$r_t + \gamma V_{\pi}(s_{t+1}) - V_{\pi}(s_t)$。
当 $\lambda$ 接近1时$A_t^{GAE}$ 变成 $-V_{\pi} + \sum_{l=0}^{\infty} \gamma^l r_{t+l}$ GAE 使用整个剩余奖励序列来估计优势。记这种引入了GAE方法的单步优势为 $A_t^{GAE}(s_t,a_t)$,新的策略梯度调整为:
\(\nabla J(\pi_{\theta}) = \underset{\tau \sim \pi_{\theta_{old}}}{E_t} \left[ \frac{\pi_{\theta}(a_t | s_t)}{\pi_{old}(a_t | s_t)} A_{\pi}^{GAE}(s_t, a_t) \nabla log \pi_{\theta}(a_t | s_t) \right]\) 由于 $\nabla f(x) = f(x) \nabla log f(x)$,上式可以改写为: \(\nabla J(\pi_{\theta}) = \underset{\tau \sim \pi_{\theta_{old}}}{E_t} \left[ \frac{\nabla \pi_{\theta}(a_t | s_t)}{\pi_{old}(a_t | s_t)} A_{\pi}^{GAE}(s_t, a_t) \right]\) 我们的优化目标变成: \(\arg\max_{\pi_{\theta}} J(\pi_{\theta}) = \underset{\tau \sim \pi_{\theta_{old}}}{E_t} \left[ \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\theta old}(a_t | s_t)} A_{\pi}^{GAE}(s_t, a_t) \right]\)
如何学习critic/critic_loss 演化过程
critic模型可以提供可靠的token级别的中间价值估计(critic用来计算$v(s_t)$的,作为一个baseline),在RLHF场景,因为PRM比较难,那么存在下面的计算reward的方式:
- 对于t如果是中间token,那么其通常r=0(或者为了防止模型崩坏加的微小 KL 散度惩罚)。
- 对于t是结尾的token,那么其通常等于奖励模型打出的得分。
critic模型的另外一个作用是:可以将最后的 Reward 分配到中间步骤(Token-level)。他是如何做到的呢?假设已经有了一个训练好的critic模型,它可以判断当前已经生成的句子的好坏程度。对于中间token的优势,上文提到我们有GAE来计算:假设简略版本的GAE是这 \(A_t \approx r_t + \gamma V_{\pi}(s_{t+1}) - V_{\pi}(s_t)\)
由于中间token的奖励是0(或者微小的负的kl散度),$\gamma =1$,$0 < \lambda < 1$。那么
\[A_t \approx V_{\pi}(s_{t+1}) - V_{\pi}(s_t)\]因此一个好的critic模型可以:可以将最后的 Reward 分配到中间步骤(Token-level)
说如何计算/训练$V^\theta(s)$?
- Monte-Carlo(MC) based approach。 $V^\theta(s)$ 与 $G_t^{\prime}$ 越接近越好。约束是你得拿到完整的episode(比如你得玩完整场游戏,因为要算$G_t$)。

- Temporal-difference(TD) approach。$V^{\theta}(s_t) - \gamma V^{\theta}(s_{t+1}) $与$r_t$越接近越好。适合无法拿到完整的episode的场景。

PPO理论推导+代码实战 不如这里详细。
关于critic_loss 第一想法是: $critic_loss =(R_t + \gamma * V_{t+1} - V_{t})^2 $
最小化TD Error(TD误差就是预测误差:实际观察到的和预测的差距)就可以训练一个预测状态价值的Critic model,critic优化是:
\[\arg \min_{V_{\pi}} L(V_{\pi}) = E_t[(r_t + \gamma V_{\pi}(s_{t+1} - V_{\pi}(s_t))^2)]\]Reward Model提供环境的基础反馈信号(即$r_t$),是Critic学习的输入。Critic Model将即时奖励转化为长期价值估计,指导策略优化方向。
- 只有Reward Model:只能提供即时奖励信号(如生成完整句子后的总分数),但无法评估每个 token 或部分响应的长期价值,使策略更倾向于选择长期回报更高的动作。
- 只有Critic Model:若奖励函数未知(如逆强化学习),Critic无法凭空学习价值函数。 在PPO中,Reward Model提供基础的真实反馈,而Critic Model将其转化为长期价值估计,两者缺一不可。
online/offline policy
在强化学习中,策略可以根据它们与数据生成策略的关系被分类为 on-policy 或 off-policy。这两种方法在处理经验数据和更新策略时有所不同,
-
On-policy 方法直接从目标策略(即当前学习和评估的策略)中采样数据,它要求学习算法和行为策略是一致的,即生成数据的策略必须是当前优化的策略。让模型自己生成轨迹,然后给个评分,比如用当前模型对一批问题生成回答,然后根据这些回答的质量(奖励)来调整模型参数,让它下次说得更好。这里的数据和模型是 “同步” 的 —— 数据来自 “现在的模型”,优化的也是 “现在的模型”。the agent learned and the agent interacting with the environment is the same.PS: 就好比帅哥追美女的某些招式/经验对普男反而有害。
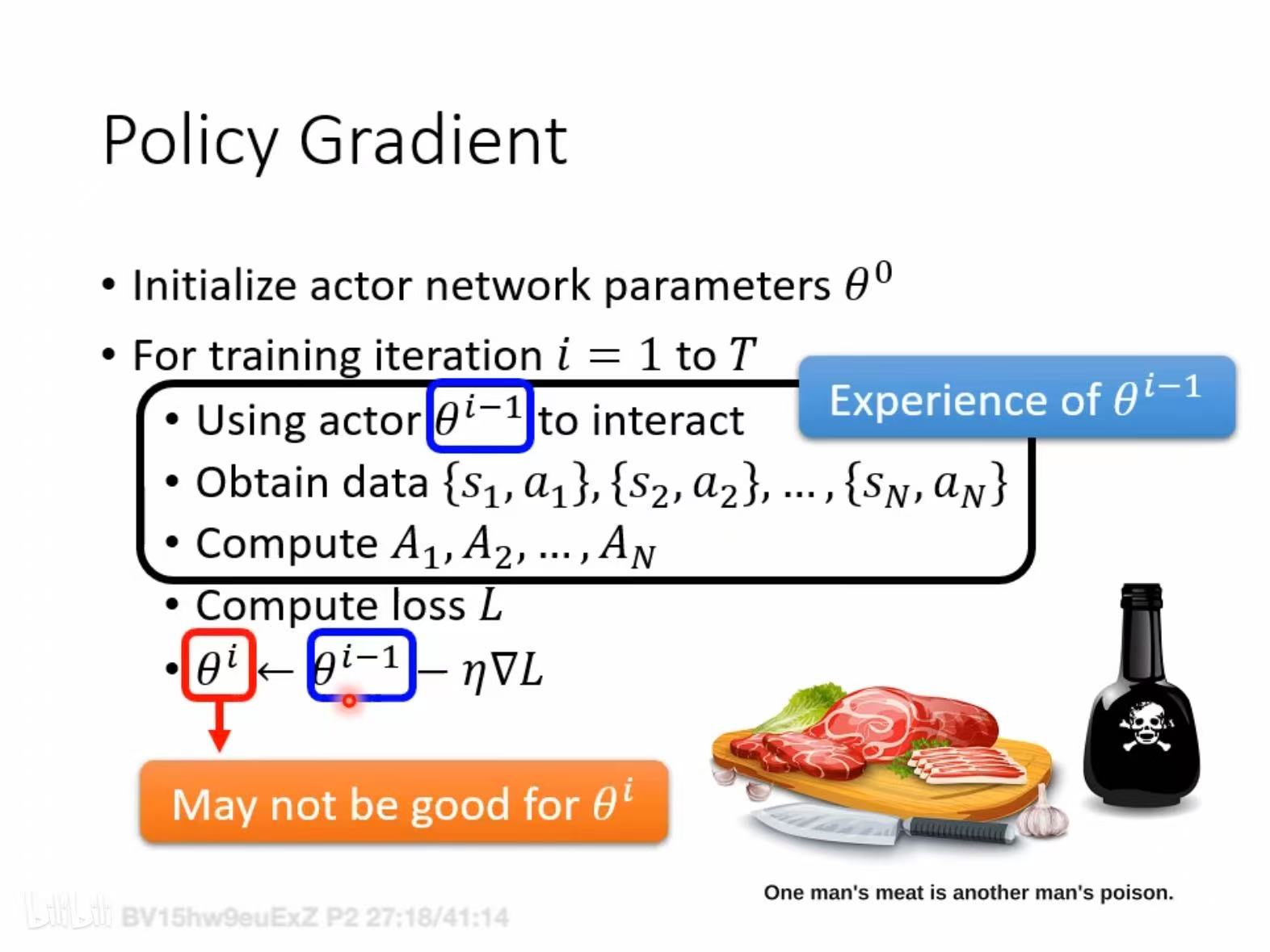 也就是在传统supervisor learning中,training data都是事先准备好的,无论跑多少次Epoch 都是一批training data,而对与rl 来说,参数要更新多少次,training data 就要更新多少次,用本轮的$\theta$ 输出的
也就是在传统supervisor learning中,training data都是事先准备好的,无论跑多少次Epoch 都是一批training data,而对与rl 来说,参数要更新多少次,training data 就要更新多少次,用本轮的$\theta$ 输出的<s,a>计算<s,a,A>来更新$\theta$,体现在代码上就是training data产生在for循环之内,也是为何rl比较耗时的原因。当前策略 $\pi_\theta$-> 生成rollout→计算奖励→更新参数$\pi_{\theta^\prime}$ →新策略→生成新rollout→ …
-
Off-policy 方法允许从与目标策略不同的行为策略中采样数据(找外面现成的答案,让模型学着模仿)。比如训练时用的数据不是当前模型生成的,而是来自 “别人”(比如人类专家写的回答、更强的模型生成的回答,或者过去版本的模型留下的回答)。虽然这些回答不是当前模型自己说的,但可以帮它更快学到正确的模式。the agent learned and the agent interacting with the environment is different.
on-policy好比自己走万里路,自己从自己的经验中学习,但问题在于,反馈太稀疏了。无论轨迹多长,一个训练回合只给一个评分。比如模型生成了 1000 个 token 的解题过程,最后告诉你错了,但到底是哪一步错了?是运算顺序错了,还是算术本身错了?不知道。这种稀疏反馈让 RL 效率很低。off-policy 类似于从别人的经验中学习,最常见的做法就是 SFT,用精心标注的数据集训练。这些数据可以来自表现很好的老师模型。但这有个问题,学生学到的是老师常遇到的上下文,不是自己会遇到的上下文。一旦学生早期犯了一个老师不会犯的错误,后面的状态就跟训练时看到的越来越远,这就是 exposure bias。这个问题在长序列上尤其严重。还有个问题,学生可能学到了老师的风格和自信,但不一定学到了老师的准确性。这就像学生抄了老师的解题步骤,但不懂为什么这么解,换道题就懵了。
on-policy 和 off-policy 的区别,主要体现在对数据的使用上,off-policy 的训练效率会明显更高一些。一方面,off-policy 可以不等所有的 response 生成完毕,就启动模型训练;另一方面,off-policy 可以多次使用同一条数据,提高数据利用率,on-policy 则不可以。 off-policy 的模型快速熵坍缩( on-policy缓慢熵坍缩)。防止熵坍缩:加入熵 loss 和 clip higher 。
PPO叫Proximal Policy Optimization,就是揉和了online/offline policy。actor to train has to know its different from the actor to interact(产生training data的actor).
Exploration,采集trainning data时可以给actor 加一些随机性,不必每次都是s1 => actor ==> a1。

OPD/On-Policy Distillation
OPD把on-policy和offline优点结合起来,用老师模型对学生的每一步打分。让学生从自己当前的分布采样轨迹,这就是 on-policy 的含义,像蒸馏一样,由教师对每个 token 给出密集反馈,信号密度上来了。学生通过最小化与教师之间的 reverse KL 散度来更新,梯度方向是让学生在自己采样的 token 上,逐步向教师的概率分布靠近。
on-policy模型的学习内容是自己 rollout 出来的好的样本。这样做的好处有很多,举一些例子:
- 这样的模型不容易出现灾难性遗忘的问题。RL 的训练目标是“强化”自身生成的好的样本,而不是强行去拟合新的数据分布,对模型内部的知识不会产生破坏效果。
- 真正 inference 的时候会更加鲁棒。少量的 SFT 样本,只能教会模型强行记住某一条轨迹(A -> B -> C),但是一旦中途发生了些许扰动(如 A -> B’ -> ?),模型由于缺乏对轨迹的深入理解,就可能就会发生错乱。
但是 RL 也有它固有的问题,就是计算不够高效,每次 rollout 一条 trace,都只能获得一个最终的奖励信号。而对比 SFT,对于每一个 token,都有一个对应的 label 来约束更新。这样相比起来,RL 在训练中,模型从一次尝试中学到的内容太少了,效率较低。那么,能不能有一种方法,既具有 on-policy 的特征,又能像 SFT 那样,对每个 token 都加以监督呢?OPD 就是一个有效的尝试,引入蒸馏的思想来解决这个问题。核心的思想很简单,首先由 student model 来 rollout 样本(体现了 on-policy 特点);然后用 teacher model 计算每个 token 对应的 logit;最后拉近 student 和 teacher 在每个 token 上的 logit 分布即可(体现了蒸馏)。具体到实现方式层面,我们简单介绍几种常见的实现。按照Thinking Machine Lab 的实现,OPD 本质上就是通过采样的方法,优化模型策略 和教师策略 之间的 reverse KL,也就是:
\[\mathrm{KL}\big(\pi_\theta \parallel \pi_{\mathrm{teacher}}\big) = \mathbb{E}_{x \sim \pi_\theta}\Big[ \log \pi_\theta(x_{t+1} \mid x_{1..t}) - \log \pi_{\mathrm{teacher}}(x_{t+1} \mid x_{1..t}) \Big]\]在实操的时候也很简单,首先使用需要训练的模型 进行 rollout;然后再使用上面右侧的公式计算出 logit 距离 teacher 的距离作为损失函数;最后梯度下降进行计算就可以了。
三种主流 OPD 实现 |类型| 计算规则| 特点| |—|—|—| |采样 Token OPD| 仅对学生实际采样的单个 Token 计算损失| 最轻量、工业界最常用,无额外显存开销| |全词表 OPD| 对整个词表所有 Token 计算 KL 散度 |梯度最密集,但显存 / 计算成本极高| |Top-K OPD| 仅对学生概率最高的前 K 个 Token 计算损失| 折中方案,兼顾效果与成本,本文实验默认使用|
OPD 成败的两大决定性条件
- 师生必须具备兼容的思维模式。即便教师基准精度更高,若师生推理逻辑、候选 Token 偏好差异过大(初始重叠率低),OPD 会彻底失效;早期思维模式的错位造成的损失,训练后期也无法修复。OPD 学习的不是「教师的高分能力」,而是教师的推理思维范式。
- 教师必须提供学生未掌握的全新知识。思维模式匹配≠OPD 一定成功。若师生来自同一训练流水线、同源数据,即便教师规模更大、精度更高,也无法提供可迁移的新知识,OPD 依然收效甚微。模型高分 ≠ 拥有新知识。同家族不同规模模型,只是对同一数据的拟合程度不同,底层分布几乎一致,无法产生 OPD 可利用的新知识。
OPD的基本流程如下:
- On-Policy采样:学生模型根据输入prompt自回归生成完整回答(不使用教师的输出)
- 教师评分:将学生生成的序列送入教师模型,获取逐token位置的logits
- 分布对齐:计算学生分布与教师分布之间的KL,以此作为训练损失
- 反向传播:更新学生模型参数,使其在自身生成的序列上接近教师的logits分布。损失函数设计
- Forward KL
- Reverse KL
这一流程与标准SFT的区别在于步骤1(on-policy vs 离线)和步骤3(软标签分布匹配 vs 硬标签CE损失)。与RL的区别在于步骤3(密集软标签 vs 稀疏标量奖励)。
OPD 的固有缺陷与适用边界(代价与局限)
- 奖励质量随序列长度衰减(长 Horizon 失效)。OPD 存在「最优序列长度区间」(实验中 3K~7K Token 效果最佳)。
- 全局有效奖励 ≠ 局部可优化梯度。教师的逐 Token 优势信号存在各向异性(不同位置信号相互抵消),梯度幅值极小,学生无法完成局部优化。
从 OPD 到 self-distillation。OPD 单纯的方法部分已经相当简洁有效了,感觉可优化的空间不大,唯独不好处理的点在于 teacher model 怎么获得。如果按照一般的想法,teacher model 使用一个 size 很大的开源模型,那么 tokenizer 很可能和 student model 不一致,那么蒸馏的 logit 和位置就对不齐,直接导致方法用不了;另一方面,虽说做实操我们总喜欢蒸馏更强的模型(不是),但做科研我们总是想提高模型的上限,那么简单的蒸馏就做不到这点了。所以最近看到不少 paper 都采用了 self-distillation 的思想,也就是自己蒸馏自己 —— 这样就避免了 tokenizer 不统一的问题。这类工作的核心问题在于,怎么让自己 rollout 更好的结果,作为 teacher。因此不少文章给出了解决方案:可以在模型输入的 prompt 里面,把专家的解答过程(demonstration)放进去,并让模型基于专家答案,给出解答过程(成为和符合自己模型风格的样本,后续再进行训练和监督)。这样一来,能保证最终 rollout 的质量,又能保证 on-policy 的特点。
重要性采样
先不说rl,前文提到,我们可以通过足够的采样的均值来近似一个分布的期望。 \(E_{x \sim p}[ f(x)] \approx \frac{1}{N} \sum_{i=1}^{N} f(x^i)\)
当我们有两个分布$p(x)$和$q(x)$,但是又无法直接从 $p(x)$采样,但可以从$q(x)$采样时,我们可以这么描述$x \sim p(x)$下 的期望:
\[E_{x \sim p}[f(x)] = \int f(x)p(x) dx = \int f(x) \frac{p(x)}{q(x)} q(x) dx = E_{x \sim q}[\frac{p(x)}{q(x)} f(x)]\]注意从 $E_{x \sim p}$ 换成了 $ E_{x \sim q}$,通过一个 权重修正,把在 q(x) 下采样的数据“重加权”为好像来自 p(x) 的数据。其中 $w(x) = \frac{p(x)}{q(x)}$ 就叫重要性权重(importance weight),表示在 q(x) 下采样到的数据,并不都“同等重要”地代表目标分布 p(x)。
重要性权重 w(x) 调整了哪些样本更“重要”。如果某个样本在目标分布 p(x) 里比在行为分布 q(x) 更可能出现(即 p/q > 1),那它就被赋予更高的权重;反,如果 p/q < 1,它就被减弱。这个过程就叫 Importance Sampling( IS,按重要性来采样/加权)。
套一下上面的公式
\[\nabla \overline{R}_\theta = E_ [ R(\tau) \nabla \log p_\theta(\tau)] = E_{\tau \sim p_{\theta'}(\tau)} [\frac{p_{\theta}(\tau)}{p_{\theta'}(\tau)} R(\tau) \nabla \log p_\theta(\tau)]\]$ratio = \frac{p_{\theta}(\tau)}{p_{\theta’}(\tau)}$就是 importance weight。
具体到action 粒度

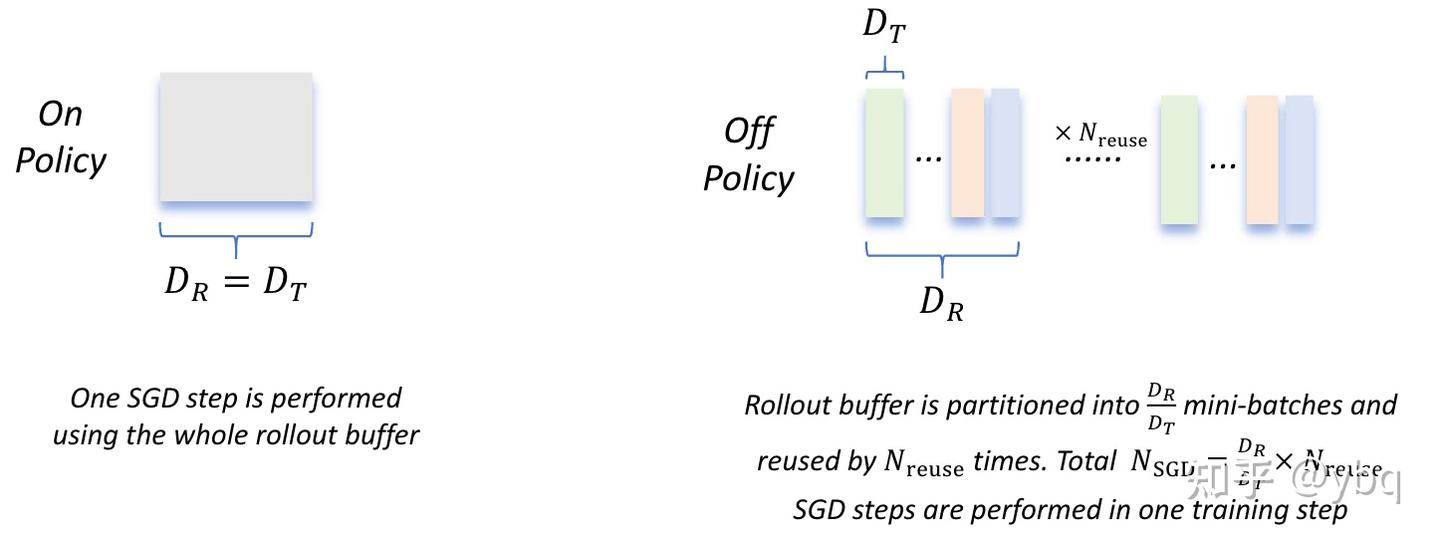
在实践中,我们为了降低采样成本,提升训练效率(采样是训练所需的,主要是不想对新的策略采样到的轨迹再计算奖励和优势),我们希望对得到的一批“经验”进行多次训练,过程如下:
- 假设某次更新完毕后,我们得到策略 $\pi_{old}$
- 我们用$\pi_{old}$和环境交互,得到一批经验数据(主要是状态价值、优势、回报)。
- 我们将把这一批回合数据重复使用k次:即我们先把这批数据喂给 $\pi_{old}$,更新得到$\pi_{\theta_0}$,我们再把同一批数据喂给$\pi_{\theta_0}$,更新得到$\pi_{\theta_1}$;以此类推,做k次更新后,我们得到$\pi_{\theta}$。
- 我们管这个过程叫off-policy(产出数据的策略和用这批数据做更新的策略不是同一个)。
- 在这k次更新后,我们令$\pi_{old} = \pi_{\theta}$。重复上面的过程,直到达到设定的停止条件为止。
但是在我们训练的过程中,由于策略已经发生了改变,采样出来的分布已经变了据此我们应该将新的策略梯度调整为:
\[\nabla J(\pi_{\theta}) = \underset{\tau \sim \pi_{\theta_{old}}}{E_t} [ \frac{\pi_{\theta}(a_t | s_t)}{\pi_{old}(a_t | s_t)} A_{\pi}(s_t, a_t) \nabla log \pi_{\theta}(a_t | s_t) ]\]这里要澄清一个容易自相矛盾的说法。 前面说 off-policy 是“用别人/旧策略产生的数据”(人类专家、更强模型、很旧的历史策略),可上面又把“同一批数据复用 K 次”也叫 off-policy,听着打架。其实 on/off-policy 不是非黑即白,而是一条谱,关键看:产生数据的行为策略,离当前要更新的目标策略有多远。
- PPO 复用的那批数据来自 $\pi_{old}$,而 $\pi_{old}$ 只是“几步梯度之前的自己”,分布只漂了一点点。所以 PPO 本质上仍是近似 on-policy:importance ratio $\frac{\pi_\theta}{\pi_{old}}$ 只是把这点小漂移修正回来,clip 则把漂移摁在一个小区间里、不让它越漂越远。正因如此,PPO 通常被归为 on-policy(或 near-on-policy),而不是真正的 off-policy。
- 真正的 off-policy,是行为策略可以离目标策略任意远的那种——replay buffer、人类示范、别的模型的输出(也就是前文那个定义)。这时分布差异大,要么靠完整的重要性采样硬扛,要么干脆换一套机制(如 Q-learning / DQN 的经验回放)。
一句话:“复用 K 次”只让 PPO 轻微偏离 on-policy,而 clip 的存在,正是为了守住“轻微”这两个字——一旦 $\frac{\pi_\theta}{\pi_{old}}$ 超出 $[1-\varepsilon,1+\varepsilon]$,更新就被截断,不让它滑进真正 off-policy 那种高方差地带。
注意,重要性采样有效的前提是p(x)和q(x)分布不能差别太大,这也是为何PPO进入KL和clip的原因。
model = SFT_model
for iteration in training:
# rollout
responses = model.generate(prompts)
logprob_old = model.logprob(prompts, responses)
rewards = reward_model(prompts, responses)
advantages = compute_advantage(rewards)
# PPO update
for epoch in range(K):
logprob_new = model.logprob(prompts, responses)
ratio = exp(logprob_new - logprob_old)
loss = PPO_loss(ratio, advantages)
optimizer.step() // model参数更新,model_old ==> model_new
- Epoch 0: 此时 weights_new == weights_old,所以 ratio 为 1。
Optimizer.step(): 权重由 $w$ 变为 $w - \eta \cdot \nabla L$。- Epoch 1: 当你再次调用 model.forward,模型内部使用的是更新后的权重,产出的 logprob/logits 自然就变了
- 如果这次更新是成功的,模型会倾向于给那些 advantage(优势)为正的 responses 分配更高的概率。
- 于是,同一个 responses 在新模型下的 logprob_new 就会变大。
ratio = exp(logprob_new - logprob_old) 正是 PPO 能够进行 K 次迭代的关键。如果没有这个比率:一旦 optimizer.step() 更新了权重,之前的 responses 就不再是由当前模型/model_new 产生的了(分布发生了偏移),按理说这些数据就该作废。有了这个比率:它在数学上补偿了“旧数据”和“新模型”之间的分布差异,使得我们可以对同一批数据反复学习 K 次,极大地提高了计算效率。
总结一下
换个角度看,整篇的主线其实就一条加工链:把原始 reward 加工成真正用来更新策略的信号 $A_t$。
\[\underbrace{r / R(\tau)}_{\text{绝对、给定}}\ \xrightarrow{\ \text{减 baseline}\ }\ \text{相对好坏}\ \xrightarrow{\ \text{credit 分摊}\ }\ \underbrace{A_t}_{\text{相对、单步}}\]下面这两个问题,正好对应加工的两步——减 baseline(相对化)与 credit assignment(分摊到每一步);各家算法的差别,也都落在这两步怎么做上。
- 绝对优势问题(没有减去baseline导致方差大) 。不同轨迹的 $R(\tau_i)$ 是不同的,而且我们是采样了一些轨迹,如果我们采样的轨迹 $R(\tau_i)$ 都是正的,把轨迹中对应的动作都提高,但一些我们没有采样到,是正确答案的轨迹对应的动作就得降低,因为,我们不希望奖励总是正的,而是要减去一个基线(平均回报),表示相对优势。只有一个动作相比相对优势是正的,我们才提高其动作的概率,如果相比相对优势是负向的,我们要降低其动作的概率。
- 价值评估函数 ==> 入状态价值函数和动作价值函数 ==> 优势价值函数=动作价值函数-状态价值函数
- 绝对优势 ==> 引入baseline, baseline实现很多,PPO(value模型),GRPO(组内平均值),REINFORCE++(batch内平均值)
- 信用分配问题 (Credit Assignment Problem)。信用分配粒度过粗(细粒度的reward分配)。一个轨迹(序列)的整体的回报很高,不能说明他的每一个动作都好,我们对轨迹中所有的动作都使用相同的回报是否合理?我们希望对一个动作能有两种方法衡量其价值:1)评估动作当下的影响(单步回报);2)又能体现动作对后续策略轨迹的长远效益。(轨迹整体回报)
- 有两种典型的方法:蒙特卡洛法(MC)和时序差分法( TD) 1. Monte Carlo 方法采用最直观的评价方式:一句话最终好 → 这句话里所有 token 都好;一句话最终坏 → 所有 token 都坏,如果整句话得了 +10 分,那每个 token 都应该更常出现;如果得了 -10 分,每个 token 都应该更少出现。每个 token 获得相同的梯度信号,无法区分贡献度。 2. TD 引入一个新角色:Value Function(价值函数)V(s),也叫 Critic(评论家),它是一个预测未来 reward 的模型(通常是另一个神经网络)。它的定义是:V(s) = “从当前上下文 s 开始,我预计这句话最终能拿多少分?”
以最简单的 TD(0)(TD是一个算法家族名) 为例,最简单的 TD(0) 算法定义 TD 误差 (TD Error): \(\delta_t = r_t + \gamma V(s_{t+1}) - V(s_t)\)
其中:
- $V(s_t)$:生成这个 token 之前,我预计未来能得多少分
- $r_t$:生成这个 token 立即获得的奖励(LLM 场景下通常为 0)
- $\gamma V(s_{t+1})$:生成这个 token 之后,我现在预计未来能得多少分($\gamma$ 是折扣因子,通常接近 1)
- $\delta_t$:实际 vs 预期的差距
TD的关键点在于:每个 token 的责任被局部化了,每个 token 不再为整句话的最终命运负责,只为”我这一步有没有让情况变好”负责。
- TD 没有用最终 reward!
- TD 没用整条轨迹!
- 而是只用了当前估计和下一步估计
- 让误差被”局部化”在一步之内
但是需要注意的是,TD 不能直接用于策略更新!TD 误差 $\delta_t$ 是用来训练 Critic(价值函数)的:$V(s_t) \leftarrow V(s_t) + \alpha \cdot \delta_t$,但我们真正要做的是更新策略(Policy)——改变 LLM 生成每个 token 的概率分布。我们还需要把 TD 思想转化为策略梯度信号。这就是 Advantage 的作用:把TD 思想用在策略更新上。Advantage 不是问”这个状态有多好”(Value),而是问:”在这个状态下,选择这个 token 比平均水平好多少?”
\[A(s_t, a_t) = Q(s_t, a_t) - V(s_t) = "选这个token的价值" - "这个状态的平均价值"\]- $Q(s_t, a_t)$:在状态 $s_t$ 下选择 token $a_t$ 之后的期望总奖励(Action-Value Function)
- $V(s_t)$:在状态 $s_t$ 下,不管选什么 token,平均能得到的期望奖励(State-Value Function)
Advantage 的意义:
- A > 0:这个选择比平均水平好 → 增加概率
- A < 0:这个选择比平均水平差 → 降低概率
- A ≈ 0:这个选择就是平均水平 → 不需要调整
梯度演进
-
REINFORCE 的梯度:$\nabla \log \pi(a_t s_t) \times G_t$ -
当我们把它写成更通用的形式,可以用任何”优势估计”来替代 $G_t$:$\nabla \log \pi(a_t s_t) \times A_t$ - 在 Monte Carlo / REINFORCE 中:$A_t = G_t - V(s_t) = \text{(实际获得的总奖励)} - \text{(之前预期的总奖励)}$
- 在 TD-based 算法中:$A_t = \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t)$
-
有了 Advantage,策略梯度更新变成:$\nabla \log \pi(a_t s_t) \times A(s_t,a_t)$
缺点
rl最大的缺点:效率极低。模型往往要把整个任务完整跑一遍,等到最后才知道自己做得对不对。只有在这一次尝试彻底结束后,它才能收到一个简单的结果信号。想象一下,一个系统花了几十步、上百步去写代码、下棋或解题,最后得到的只是一个模糊的提示:成功还是失败。它不知道哪一步做得好,也不清楚哪一步出错,只能靠反复试验去猜。往往要重复上千次,才能从偶然的成功里提炼出一点有价值的经验。低效的根源在于,它几乎只看结果。模型在完成一项复杂任务时,无论中间经历了多少误判和偶然,只要最后成功,就会被判定为正确。它学到的不是理解,而是取巧。强化学习让模型更会迎合奖励,却未必更聪明。现实世界的目标是模糊的、多维度的,根本无法被单一的奖励函数概括。Karpathy 更看重的,是让模型在每一步中学会理解。不是完成任务后才得到结果,而是在过程中就能意识到自己哪里做得好、哪里需要调整。这需要更细致的过程监督与反思机制,让模型能像人一样边做边学。人类的智慧并非来自被奖励,而是来自对错误的体察与对过程的理解。
留下评论